
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 개발자취업준비
- 코딩국비지원
- 블로그와 친해지기
- 코딩교육
- 코딩배우기
- 개발자포트폴리오
- 코딩 부트캠프
- 개발자 채용설명회
- 코딩 교육
- 엘리스 AI 트랙
- 엘리스AI트랙데모데이
- 신입개발자
- 엘리스
- 인공지능모델학습
- 개발자취업특강
- 개발자이력서
- 코딩부트캠프
- 이미지처리프로젝트
- 송리단길
- 개발자 포트폴리오
- 와탭랩스
- 코딩테스트
- 엘리스AI트랙
- 부트캠프프로젝트발표
- 웹개발포트폴리오
- 코딩 배우기
- 팀프로젝트
- 웹개발프로젝트
- 프로젝트마무리
- 코딩 국비지원
Archives
- Today
- Total
자몽이 조아
11주차 엘리스 강의 정리 - Pandas 심화 알아보기 본문
반응형


마스킹연산

df[column].str.contains(문자열) : column의 시리즈의 str 데이터에서 문자열을 포함하면 True
df[column] == 문자열 해도 같은 결과가 나온다.
df.Column.str.match(문자열) : 컬럼의 시리즈에서 str데이터에서 문자열을 포함하면 True
match부분에서 정규표현식을 쓰게 되면 더 자세히 검색 가능.


apply 를 통해서 함수로 데이터 다룰 수 있음.
df["Num"].apply(square) : 오른쪽 시리즈데이터.
df["Squre"] = df.Num.apply(lambda x: x **2)


딕셔너리로 key value 가져와서 replace를 하는 함수를 apply로 적용시켜서 값을 변환.
apply안에 딕셔너리를 넣어서 key를 value로 변환할 수 있다.
inplace=True : df["Sex"]=~~~로 시리즈로 다시 넣어주지 않아도 그대로 바뀜.


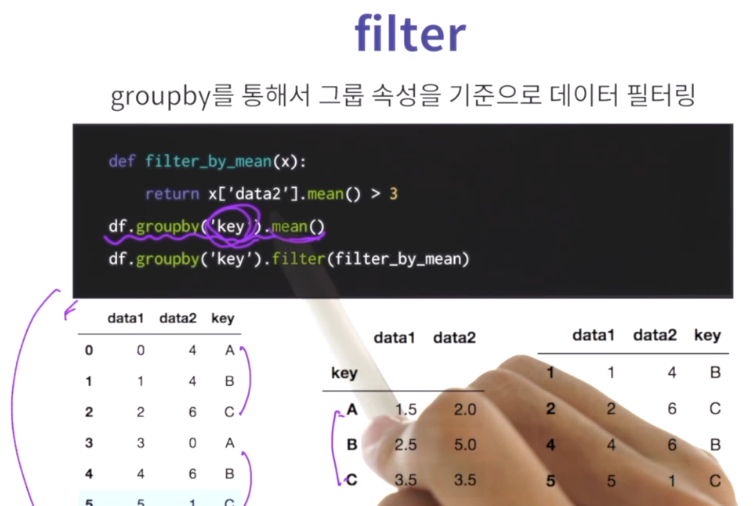
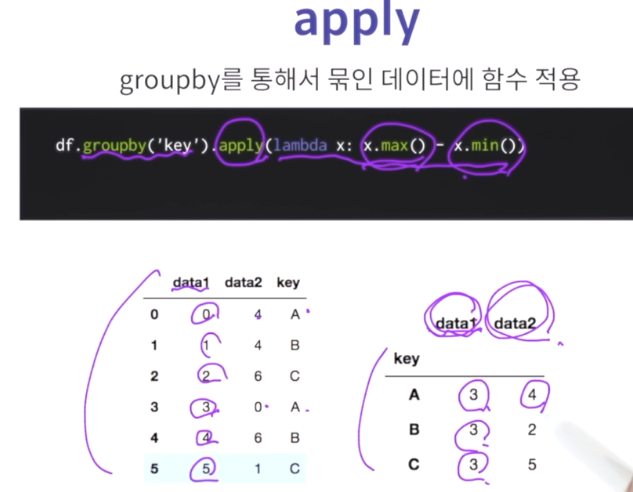





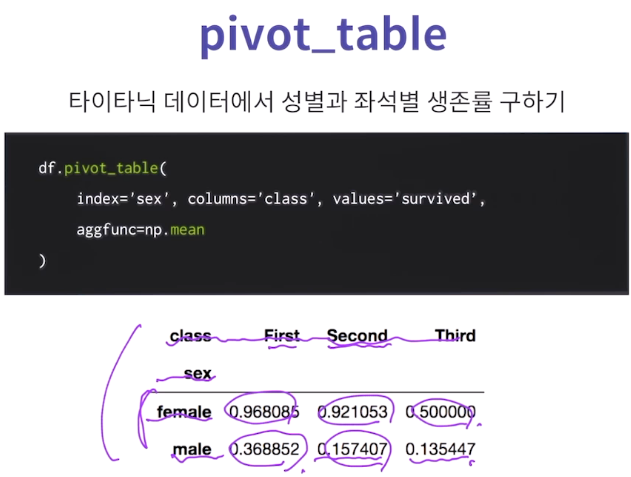
데이터를 어떻게 채우느냐에 대한것이 aggfunc,
np.mean 즉 각 인덱스에 대해서의 연산 후의 값.

반응형
'엘리스 활동' 카테고리의 다른 글
| 팀프로젝트 전 능력 키우기(사이드 프로젝트 하기) (0) | 2021.09.25 |
|---|---|
| 엘리스 AI 개발트랙 - 스터디, 취업 로드맵, 프로젝트를 진행하며 (0) | 2021.09.10 |
| 11주차 엘리스 강의 정리 - Pandas 기본 (0) | 2021.09.02 |
| 11주차 강의 정리- NumPy (0) | 2021.09.02 |
| 11주차 실시간강의 정리(1) (0) | 2021.09.01 |
'엘리스 활동' Related Articles
more




Comments