
넘파이를 사용하는 이유:
파이썬 리스트로도 계산할 수 있으나, 넘파이는 리스트에 비해 빠른 연산을 지원하는 메모리를 효율적으로 사용한다.
넘파이를 보통 np로 사용.
array는 리스트와 다르게 단일타입으로 구성되고 타입은 dtype으로 확인하고 다른 자료형으로 보고싶으면(int) 형전환된 형태로 확인도 가능하다. astype.

np.zeros(개수,dtype=자료형) : 개수만큼 자료형으로 0을 채움.
np.ones((i,j),dtype=자료형) : i높이의 j길이 배열을 자료형으로 1로 채움.
np.arange(start,end,stop) : start부터 end까지 stop의 간격으로 이루어진 배열 생성
np.linspace(start,end,개수) : start부터 end까지 일정한 간격으로 개수만큼의 배열 생성
np.random.random((i,j)) : i높이 j길이 의 2차원 배열을 랜덤한 수로 채운 배열 생성
np.random.normal(0,1,(i,j)) : 표준정규분포에서 데이터를 뽑아 i높이 j길이의 배열 생성
np.random.randint(start,end,(i,j)) : start부터 end사이의 랜덤한 정수를 뽑아 i높이j길이의 배열로 생성


arr.ndim : 배열의 차원
arr.shape : 배열의 모양
arr.size : 요소의 개수
arr.dtype : 배열의 타입
type(arr) : 파이썬에서의 자료형
slicing방법은 파이썬 리스트와 비슷.
x[::2]는 2씩 건너뛰면서 출력하는 것을 뜻함.
콤마로 구분하여 하나씩 출력도 가능하고, 스플라이싱을 쓴 것을 콤마로 구분할 수도 있음.


| reshape는 1차원배열을 다른형태로 바꿔준다. concatenate는 array를 이어붙임. arr.reshape((i,j)) |
np.concatenate([arr1,arr2]) array를 가로방향으로(기본) 이어붙여줌 axis가 1이 기본 |


axis가 0이면 세로로, axis가 1이면 가로로 붙인다.


어느인덱스를 기준으로. axis가 0이므로 세로방향의 인덱스 기준으로 나눠짐.
upper는 윗부분, lower는 아래부분 배열을 지칭.
axis가 1이면 가로방향의 인덱스를 기준으로 나눠짐.
left 는 왼쪽, right는 오른쪽 배열 지칭.
axis가 0이 기본(세로방향)
각각의 원소에 덧셈을 하는 루프에 비해 기본 연산을 하게되면 훨씬 빠르다. 이것이 넘파이의 장점.
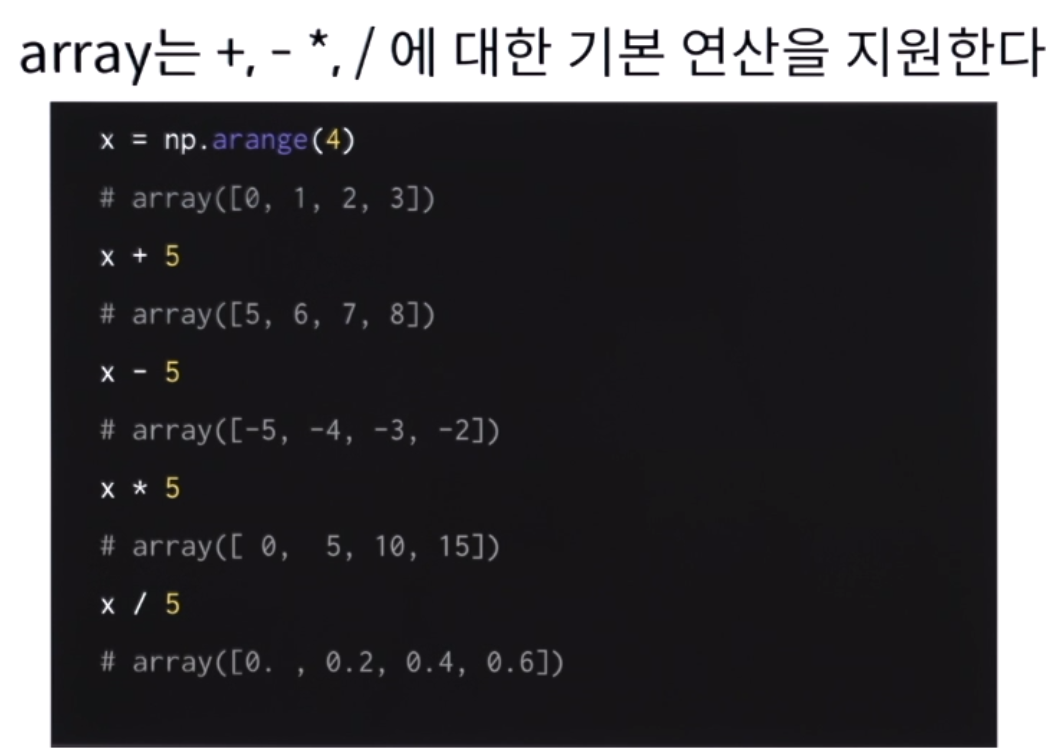

기본연산, 행렬간 연산도 가능하다.
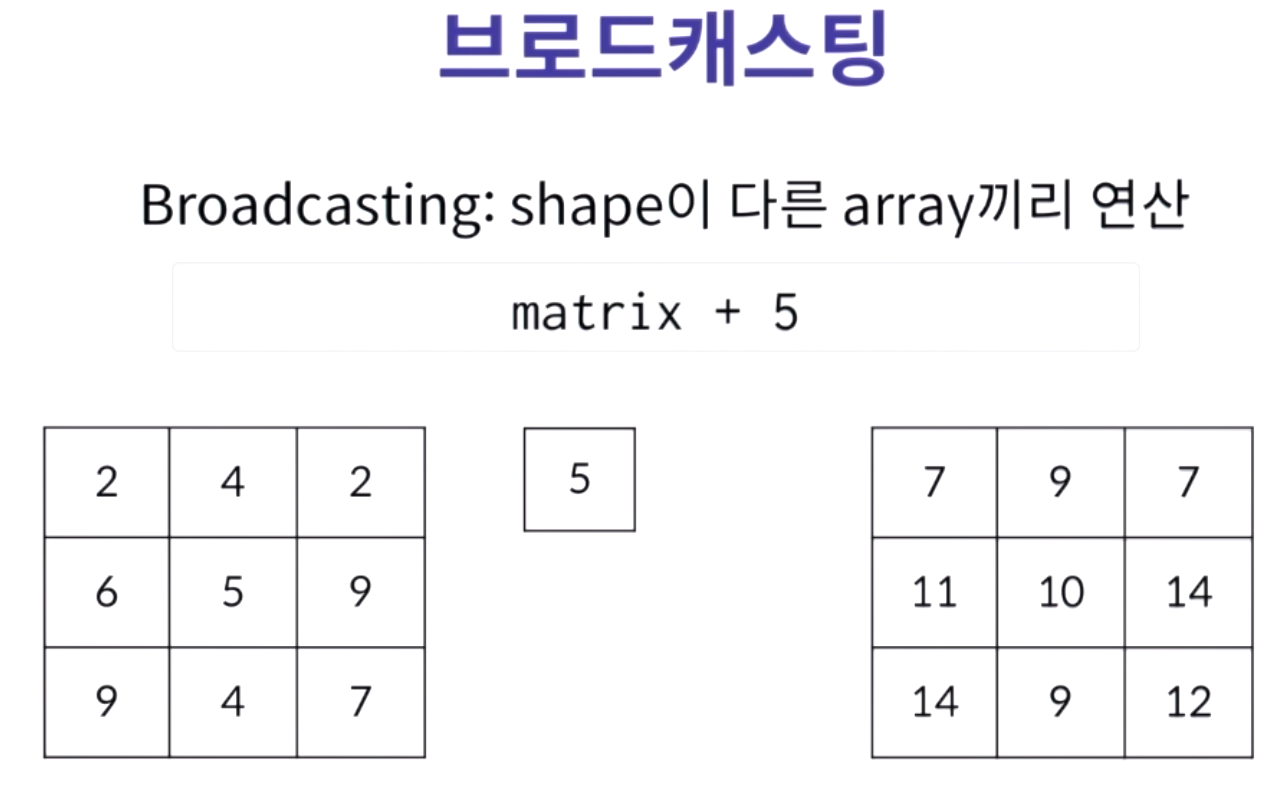
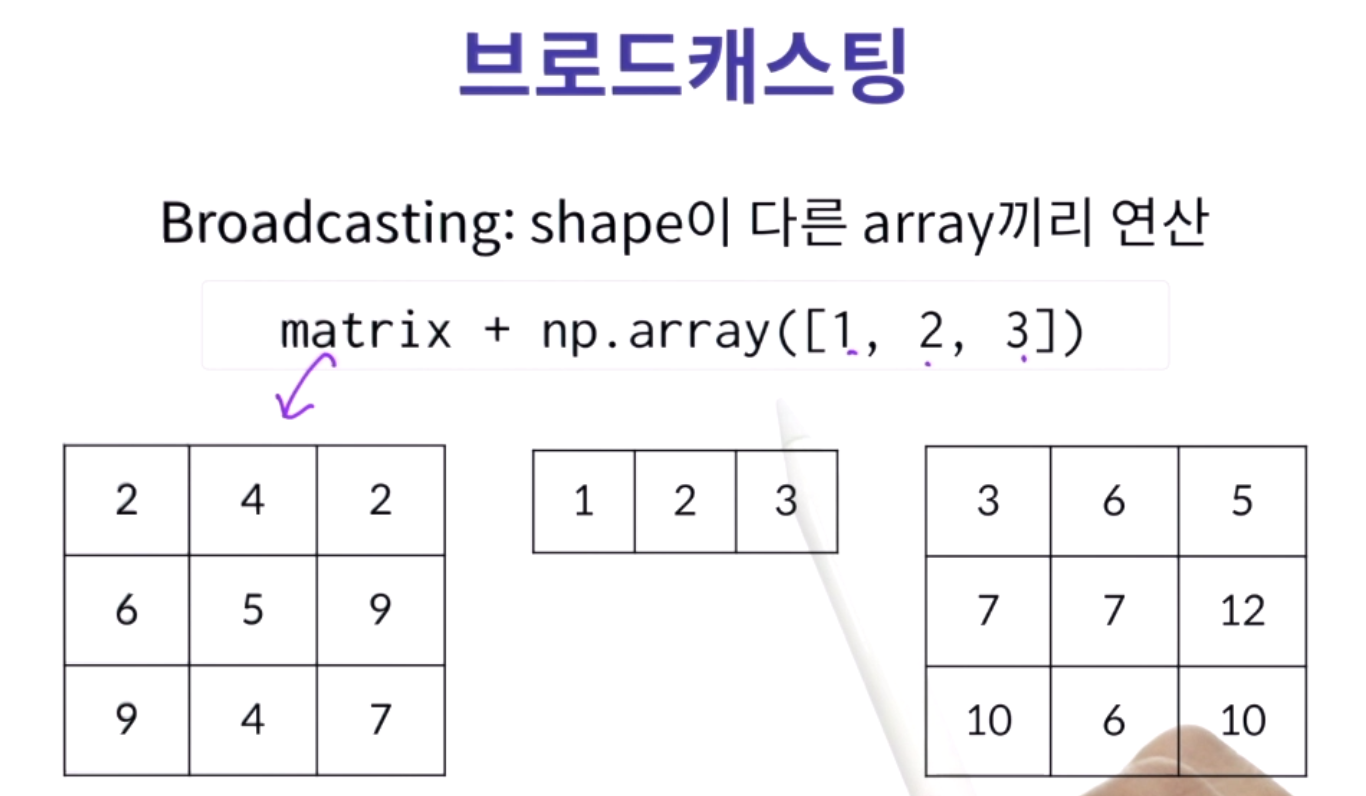
연산할수 있게끔 array의 형태 및 개수를 늘려 연산을 할 수 있다.
세로로 긴것을 가로로, 가로로 긴것은 세로로 반복되어 연산이 가능해진다.
| 0 + 0 | 1 +0 |
| 2 + 1 | 3 + 1 |
| 4 +2 | 5 + 2 |
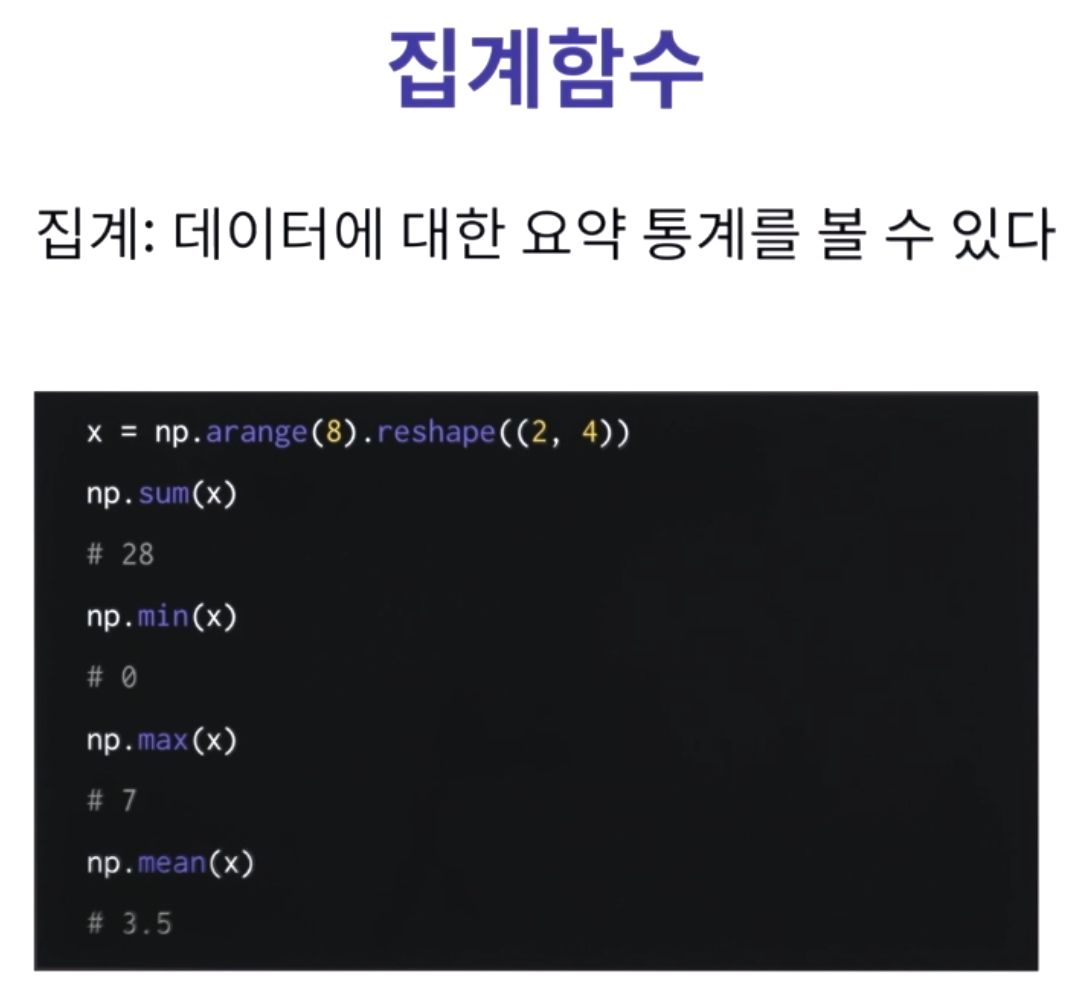

| np.sum(x) np.min(x) np.max(x) np.mean(x) |
axis값을 주게되면 각 방향의 집계함수 값을 볼 수 있다. 0 이면 각 열의 통계, 1 이면 각 행의 통계. |
각 요소의 값에대한 연산의 값을 각 인덱스에 True, False로 나타내고,
x[x<3]과 같이 연산하면 True가 되는 값만 나타낸다.
arr==0 연산을 통해 arr의 요소가 0인 부분들을 True, 0이 아닌부분들을 False로 만들고, 그 중 0즉 False인 부분을 제외하고 카운트를 해준다.
np.count_nonzero(array) : 0이 아닌 부분을 카운트
'엘리스 활동' 카테고리의 다른 글
| 11주차 엘리스 강의 정리 - Pandas 심화 알아보기 (0) | 2021.09.03 |
|---|---|
| 11주차 엘리스 강의 정리 - Pandas 기본 (0) | 2021.09.02 |
| 11주차 실시간강의 정리(1) (0) | 2021.09.01 |
| 엘리스 11주 내용정리(2) (0) | 2021.08.31 |
| 엘리스 11주 내용 정리-(1) (0) | 2021.08.31 |