11주차 엘리스 강의 정리 - Pandas 기본


행렬계산, 엑셀데이터 계산등에 용이한 데이터 프레임이라는 효율적인 데이터구조 이용.
좀더 익숙한 데이터처리.


index, data, datatype 정보가 있음.
pd.Series(data),index=index)형태

딕셔너리로도 만들 수 있다. 여기서 population.values 라고 하면 numpy array가 나온다.

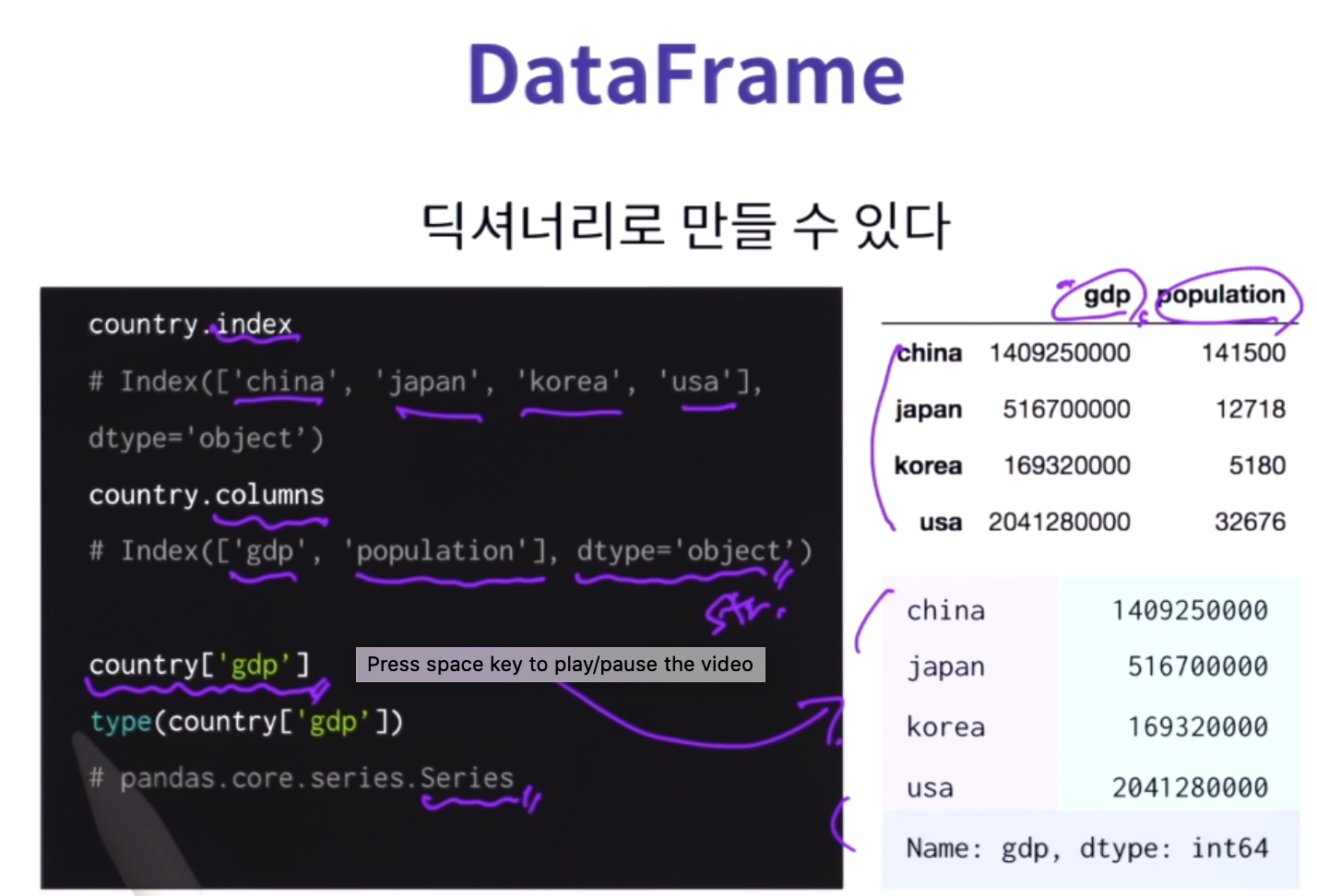
데이터 프레임: 표형태로 나타냄.
딕셔너리의 키가 인덱스가 되고 value가 데이터가 됨.
pd.DataFrame의 키는 column, value는 각 시리즈, 그리고 표에서 index는 시리즈의 키, value는 시리즈의 value다.
dtype="object" 데이터프레임에선 문자열을 기본적으로 파이썬 객체로 본다.
데이터프레임의 각 column에는 시리즈데이터가 담겨있다.
따라서 타입이 pandas.core.series.Series
시리즈데이터는 numpy array가 보강된 형태이다.


csv excel로 저장한다.
읽을 때 데이터프레임형태로 불러온다.
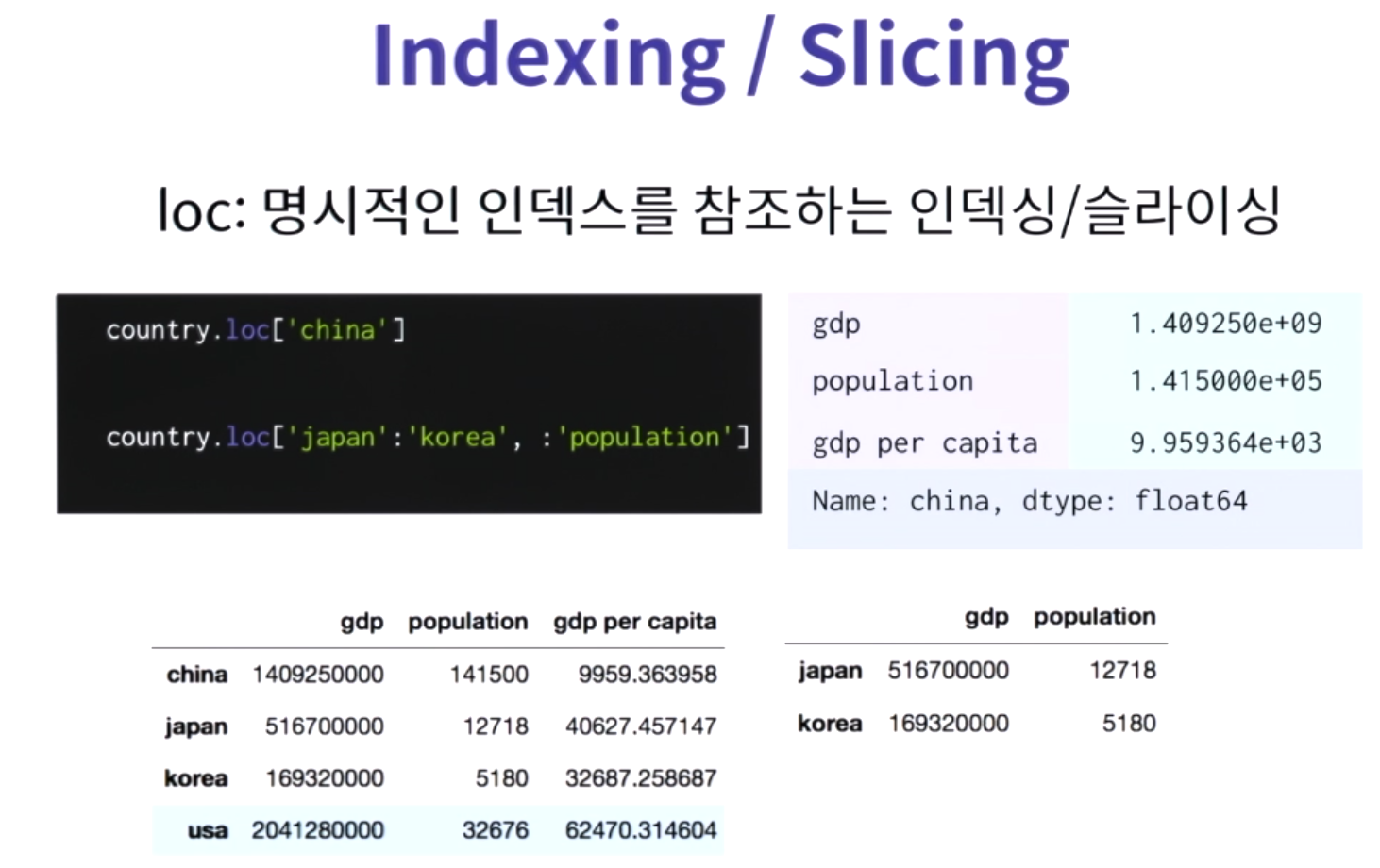

dataframe.loc[index] : 명시적인 인덱싱 참조/
dataframe.loc[index slicing, column slicing]
&
파이썬 스타일 정수 인덱싱

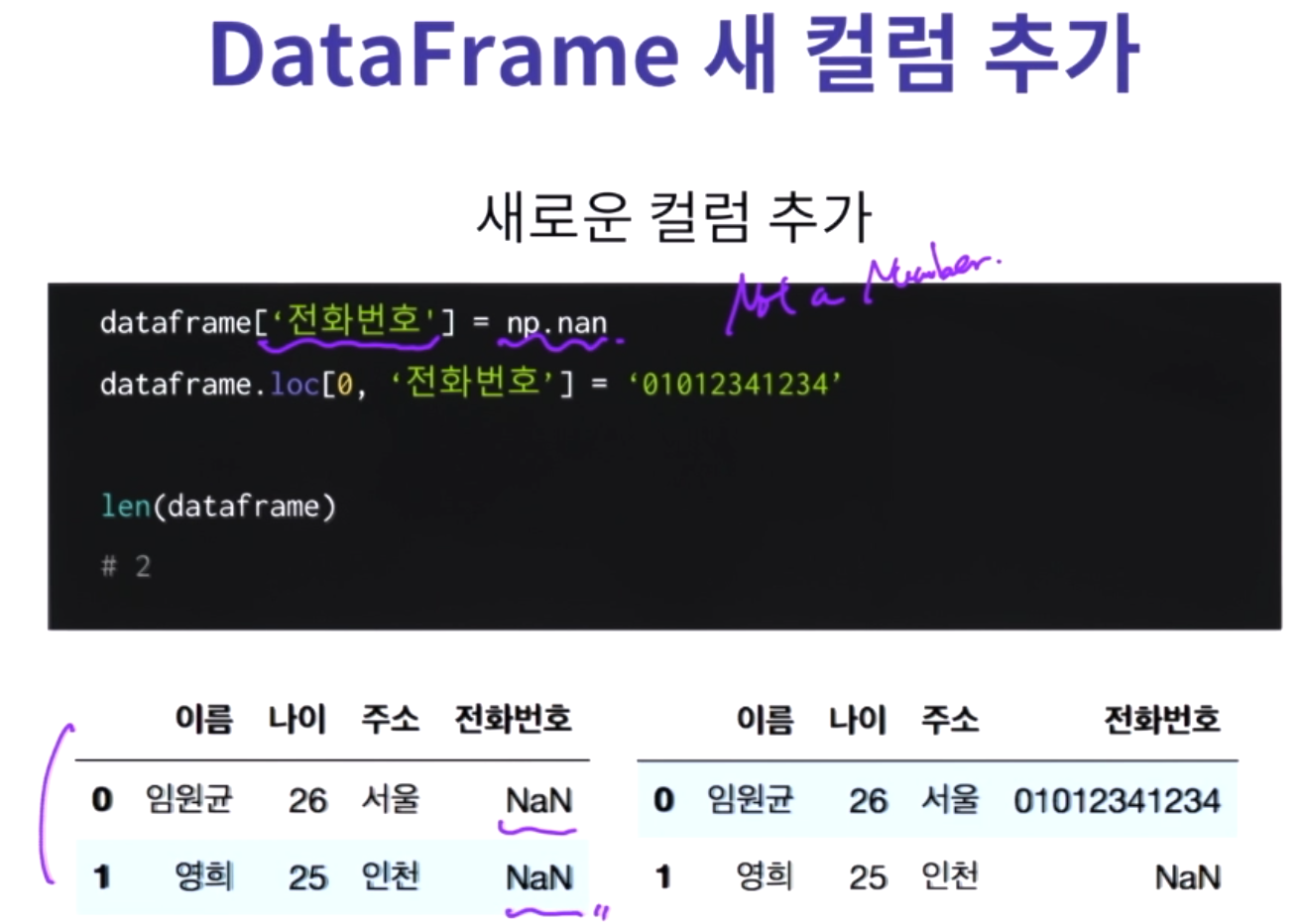
dataframe.loc[index,column]
dataframe.loc[index] = 시리즈
dataframe.loc[index] = np.nan ==> 비어있는 공간 생성
len(dataframe) ==> index개수


dataframe.isnull() : 비어있으면 True
dataframe.notnull() : 채워져있으면 True

dataframe.dropna() : 데이터가 비어있는 row를 제거
dataframe[index] = dataframe[index].filna("없음") : 데이터가 없는 시리즈의 데이터를 없음으로 대체.
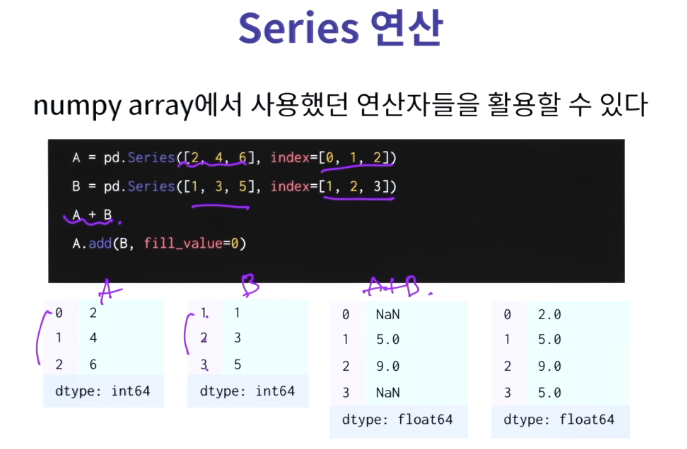

시리즈 간 같은 인덱스(시리즈에서는 같은 row column) 끼리만 연산이 되며, 한쪽에 없는 인덱스의 데이터는 NaN이 된다.
이 때 A.add(B, fill_value=0) 에서 데이터가 NaN인것을 0으로 채워서 더해줄 수 있다.

집계함수는 시리즈에서 쓸 수 있으므로 각 시리즈별 집계가 나온다.

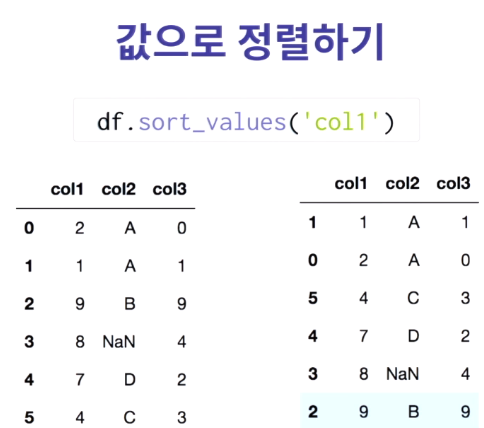
데이터프레임.sort_values(column)이라고 하면 column을 기준으로 row가 정렬된다.

ascending=False : 내림차순 정렬
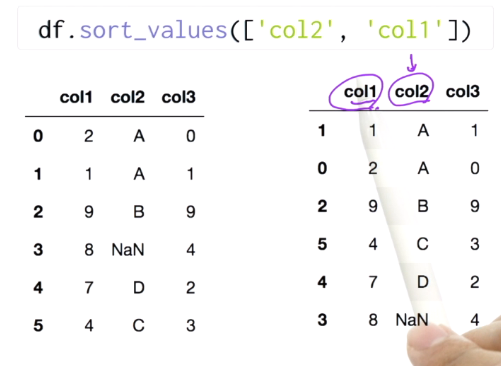
컬럼이 여러개일 때 먼저온 컬럼에 대해서 정리하고, 그 컬럼의 값이 같은 row에 대해 다음 컬럼 기준으로 정렬.